Identifying Top Accounts with Pipeline Predict
Discover how Demandbase's Pipeline Predict uses advanced AI and machine learning to help B2B sales and marketing teams accurately identify and prioritize high-potential accounts for faster, more efficient pipeline growth.


Introduction
Understanding which accounts are likely to progress through the sales pipeline is a crucial part of helping B2B Sales and Marketing teams make data-driven decisions and allocate their time and resources efficiently. At Demandbase, we use artificial intelligence and machine learning (AI/ML) to predict which of our customers’ accounts are likely to reach key points in the sales pipeline. This post will focus on one such application, Pipeline Predict, which scores accounts based on how likely they are to open a sales opportunity in the near future.
Challenges
Predicting pipeline progression in complex B2B go-to-markets is challenging due to a variety of factors:
- Incomplete and/or inconsistent data
- Complex sequences of events that occur at each stage of the pipeline, which may vary significantly from customer to customer and deal to deal
- B2B sales cycles involve multiple decision makers with different priorities and degrees of influence over long periods of time
- Potential buyers may be researching and displaying interest anonymously for a period of time before identifying themselves via attending a webinar, scheduling a demo, etc.
Why Use AI/ML?
AI/ML allows us to create a more accurate ranking of accounts because it is:
- Sophisticated: ML can detect complex patterns of activity that would be difficult for marketing and sales teams to tease out on their own
- Adaptable: every time the model is retrained, it will learn the patterns that are working now, not what was working a year or two ago
- Responsive: since the model can make new predictions frequently based on the latest data for every account, it can swiftly detect when an account is showing important buying signals and ought to be prioritized
Data Sources
Pipeline Predict ingests data from a variety of sources, including 1st party data such as Customer Relationship Management (CRM) systems, marketing automation platforms (MAPs), 3rd party data providers, and Demandbase’s own proprietary datasets. Moreover, the team is actively working on incorporating additional internal and external data sources with the goal of further enhancing Pipeline Predict. The main data sources are:
- Opportunities in our customer’s CRM: we are predicting opportunity creation, so we ingest historical opportunity data and allow our customers to filter to specific sets of opportunities they care about
- DB Intent: which relevant keywords has the account researched or been exposed to online?
- 3rd-party Intent Surge: has the account suddenly or significantly increased their exposure to relevant keywords?
- DB Site Analytics: which pages on our customer’s website has the account been visiting?
- Activities in our customer’s CRM: has the account responded to sales emails, attended a webinar or meeting, etc.?
- Activities in our customer’s MAP: has the account opened marketing emails or clicked on links within them?
- DB Firmographics: does the account have a similar location, size, or industry as the accounts that typically open an opportunity?
- DB Advertising: for customers who run advertising campaigns with Demandase, how many impressions, and clicks, and site visits can be attributed to each account in the target account list?
- DB Buying Groups: for customers who have set up Buying Groups, which activities can be attributed to members of the account’s buying group or to a specific buying group persona?
- 3rd party Funding Data: has the account recently raised a new round of funding, and how much?
- DB News: has the account been in the news recently due to leadership changes, financial results, acquisitions, etc.?
- DB Recommended Personas: for contacts that don’t have an assigned persona, we may use personas recommended by our AI model
Demandbase’s account identification capabilities allow us to link intent, page visit, and advertising data to a specific account, pulling these datasets together to understand a single account’s behavior across the web.
Model Features
For all of the activity, site visit, intent, and other data described above, the Pipeline Predict model looks at the following:
- When did the event occur and how often?
- For CRM and MAP activities, who did the activity and what is their level of seniority?
- Can the activity or event be linked to a specific campaign, webinar, or email?
Here are some examples of important features from Demandbase’s internal Pipeline Predict models supporting Demandbase’s own marketing and sales teams:
| Firmographics | The account is in the software industry |
| Intent | The account is showing intent for important keywords such as “ABM platform” and “GTM strategy” |
| Site Analytics | The account visited a relevant article at support.demandbase.com |
| CRM Activities (Salesforce) | A VP responded to a product education campaign |
Customer- and Product-Specific Models
We train separate models for each of our customers, for a few important reasons:
- To protect our customers’ private data: we don’t combine data from multiple customers’ CRMs because most of our customers ask us to keep this data separated.
- To reflect our customers’ unique characteristics: each customer has their own Ideal Customer Profile (ICP), Go-To-Market (GTM) strategy, sales cycle, persona definitions, and product portfolio. Our models need to deduce the specific activities, intent, and firmographic features that generate pipeline for each customer.
- Everyone’s activity taxonomy is different: although activity and event data may represent similar concepts across different customers, they are often named and encoded very differently in each customer’s CRM.
We also give our customers the option to create multiple Pipeline Predict models, so they can generate different scores for different product lines. This means the model is able to learn which activities tend to generate pipeline for different products, where the specific weights can be different for different product lines. Here’s an example from one of Demandbase’s customers:
| Product Line | Important Activities |
|---|---|
| Product A | CXO responded to a Salesforce campaign promoting an Analyst Report |
| Product B | Director visited a relevant web page |
| Product C | Manager, VP, or CXO responded to a Salesforce campaign promoting an eBook |
| Product D | An employee attended a webinar |
Account Sampling
Most Demandbase customers have hundreds of thousands or even millions of accounts in their CRMs. Only a small percentage of these accounts will open an opportunity during a given time period. To achieve good model performance, we need to choose a more balanced mix of accounts that have and have not recently opened an opportunity as our training data.
Additionally, when we are choosing accounts without a recent opportunity for training, we encounter further imbalances in the activity and intent features for these accounts, because the large majority of accounts in any CRM are unaware and unengaged. Since choosing accounts at random will primarily return accounts with zero activity or intent, we employ a stratified sampling approach so that we get examples of accounts without an opportunity that have a variety of different intent and activity features.
Model Architecture
We have two primary goals when selecting a model architecture for Pipeline Predict:
- We need a model that can provide reasonable predictions to as many customers as possible, even those that have fewer historical opportunities to train on
- We want a model that is as sophisticated as possible in teasing out the important events or sequences of events that lead to opportunity creation
This has led us to take an ensemble model approach:
- Customers with large opportunity datasets use a deep learning model that can detect highly complex and sequential patterns with interactions between different types of events
- Customers with relatively smaller opportunity datasets use a machine learning model that has lower data requirements yet strong predictive power
- Customers with extremely small opportunity datasets do not have sufficient data to train Pipeline Predict models
Training & Prediction Cadence
To be useful, Pipeline Predict models need to adapt to changes in marketing and sales strategies, as well as the behavior of target accounts. Every model is therefore regularly retrained, and our customers can also retrain their models on-demand through the UI. This ensures the model has an up-to-date understanding of the specific actions that are leading to opportunity creation in the recent past.
Frequently updating the predictions for each account is critical to detecting high-priority accounts as early as possible, so we pull the latest data and make fresh predictions for every account every day.
New Business vs. Growth Opportunities
In the past, Pipeline Predict has been focused solely on predicting new business opportunities. In January 2025, we rolled out Pipeline Predict for Growth, which adds the capability to predict which customer accounts are likely to open growth opportunities (upsells, cross-sells, renewals).
Customer accounts are very different from non-customer accounts, both in terms of the outcome we’re trying to predict (opportunity creation) and the features we’re using to make a prediction (activities and intent). The charts below show an example of the proportion of accounts with a currently open opportunity:
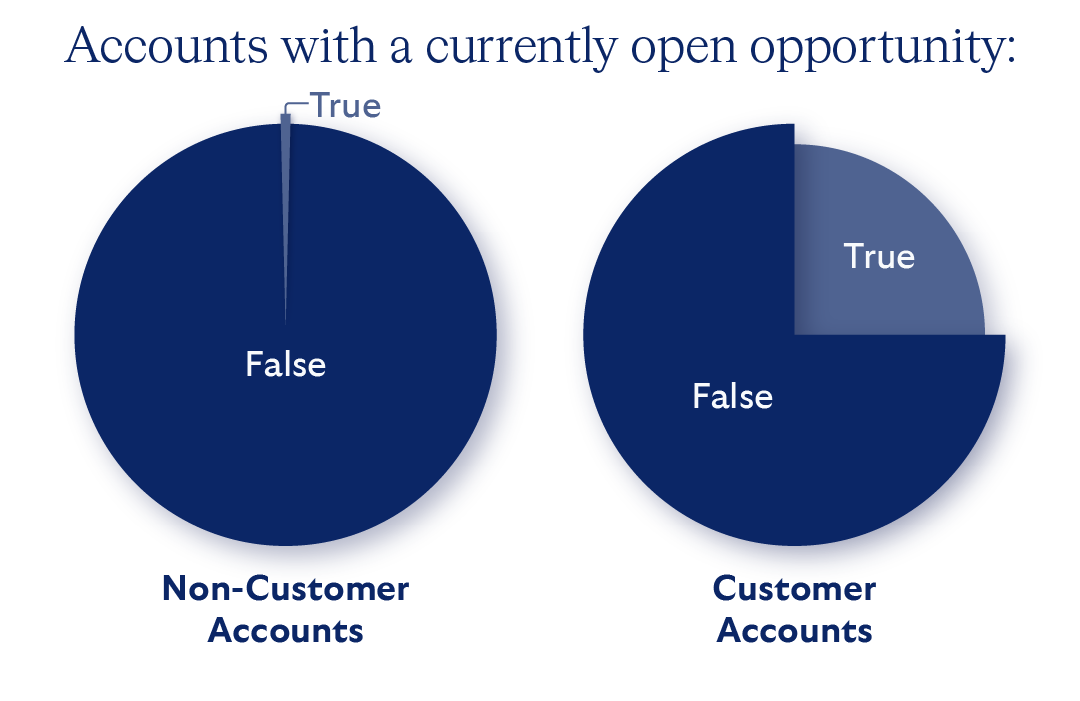
Customer accounts have fundamentally different behaviors compared to non-customer accounts, since they are already aware and likely very engaged. This means the model needs to learn different patterns of behavior that occur prior to opening a growth opportunity, and specifically, the customer accounts without an opportunity will tend to have a much larger volume of activity than the non-customer accounts without an opportunity.
Average activity counts for accounts in Demandbase’s CRM over 12 months:
| Non-Customer Accounts | Customer Accounts | |
|---|---|---|
| Page Visits | 0.7 | 292.0 |
| CRM & MAP Activities | 0.7 | 351.9 |
| Weeks of High-strength Intent | 0.3 | 5.8 |
| Intent Surge activities | 1.2 | 39.9 |
How Well Does Pipeline Predict Work?
The goal of Pipeline Predict is to focus sales and marketing efforts onto the accounts most likely to open an opportunity, so the most important way we measure success is by checking whether the accounts that received a high Pipeline Predict score actually opened an opportunity soon afterward. We call this metric true precision.
True Precision = Accounts with a High Score 30 Days Ago and Opened an Opp within Last 30 Days /
Accounts with a High Score 30 Days Ago
We can also look at a benchmark to determine how good a model’s true precision is. Specifically, we want to compare the model’s true precision to what a sales rep might achieve without the model (more on this below).
Relative Lift = Model’s True Precision /
Sales Rep’s True Precision
A healthy Pipeline Predict model should meet the following criteria:
- The true precision should be higher when the score is higher. The table below shows true precision results for one of our customers. These results mean that if a sales rep focuses on targeting the “Highly Likely” accounts, almost 1 in 3 of these accounts will open an opportunity in the next 30 days.
Pipeline Predict Label # Accounts with Label True Precision (TP) Relative Lift Highly Likely 2,125 31.5% * 2.9X Likely 13,904 7.6% 1.9X Unlikely 1,031,194 0.0005% 0.37X
* True precision of 31.5% may sound low compared to other AI/ML applications, but we are operating in the context of sales and marketing outreach, where very low success rates are the norm[1]. In this context, relative lift (see below) is a normalized alternative metric. That brings us to our second criterion: - The true precision for “Likely” and “Highly Likely” accounts should be higher than what a sales rep could achieve on their own. We can approximate the sales rep’s results by ranking accounts by the number of recent engagement minutes. In the table below, if we compare the top ~2,000 accounts as ranked by Pipeline Predict (Highly Likely) versus the top ~2,000 accounts as ranked by the sales rep, we can see a relative lift of 2.9X. In other words, Pipeline Predict is 2.9 times more effective at identifying accounts that will open an opportunity. Relative Lift serves as a normalized performance metric, since the baseline true precision may vary from customer to customer and product to product.
Sales Rep’s Account Ranking Sales Rep’s True Precision (TP) Relative Lift: Model TP vs Sales Rep’s TP Top 2,125 accounts 10.7% Model TP is 2.9X Sales Rep’s TP Middle 13,904 accounts 4.1% Model TP is 1.9X Sales Rep’s TP Bottom 1,031,194 accounts 0.1% Model TP is 0.37X Sales Rep’s TP
No Black Boxes
Sales and marketing users always want to know why a high-scoring account got a high score, so explainability is a critical piece of Pipeline Predict models.
- Customers with large opportunity datasets use Granger causality to derive feature importances
- Customers with smaller opportunity datasets use SHAP values to derive feature importances
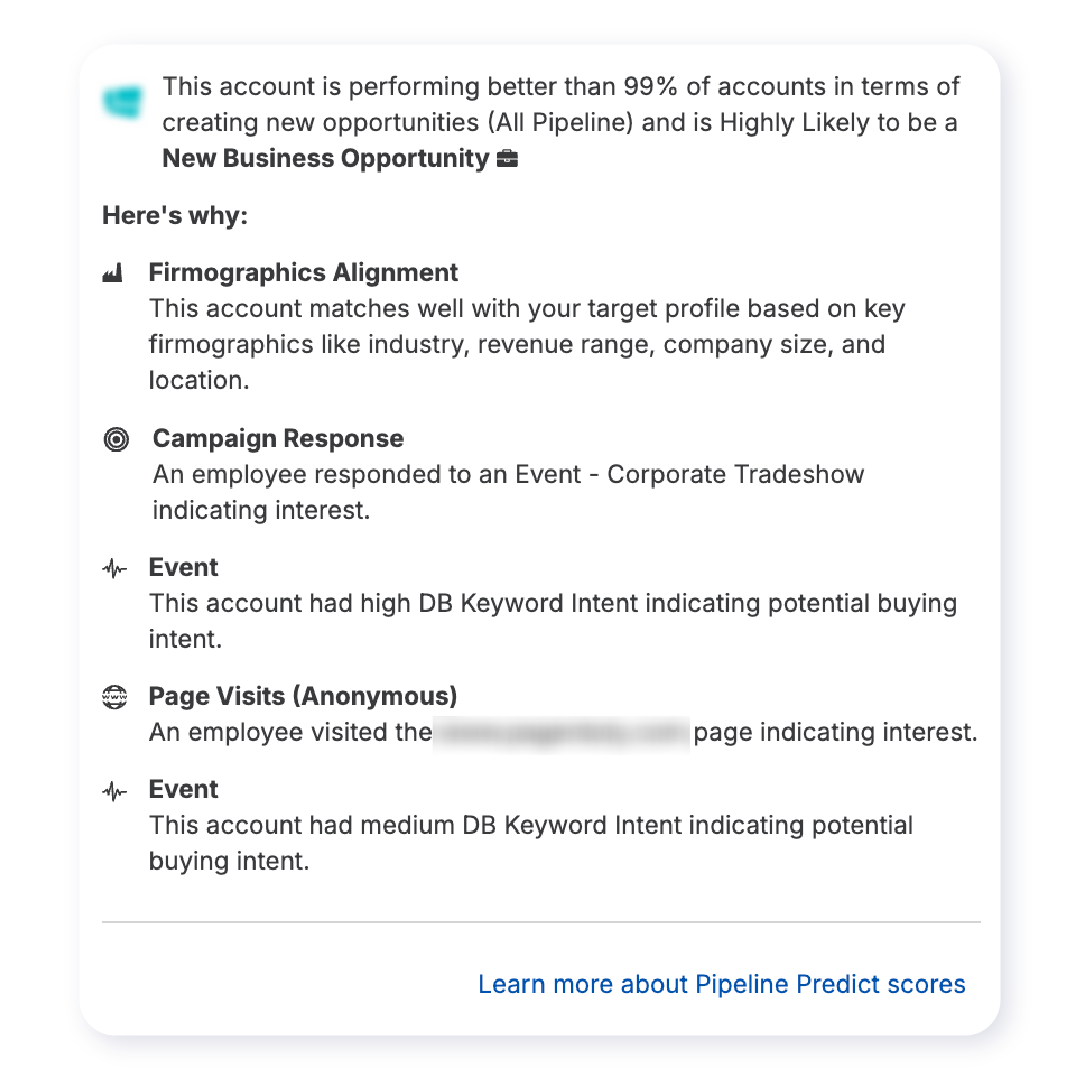
We display the important features for each account in the Demandbase UI, using an LLM to convert model feature names into human-readable explanations. These explanations tell us why a particular account is hot right now.
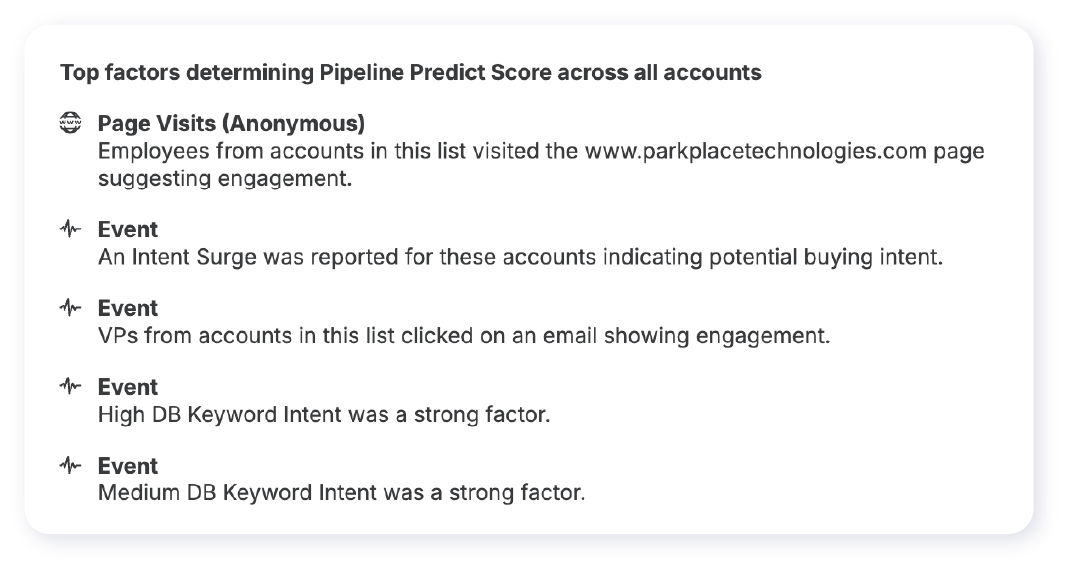
We also aggregate the account-level explainability information across all accounts in the CRM, which tells our users which features are important overall. These explanations tell us what makes a hot account in general. There are examples from 2 models below:

Conclusion
Pipeline Predict provides a powerful AI/ML solution to understanding which accounts are likely to open an opportunity. By leveraging Demandbase’s large ecosystem of first-party and third-party data in addition to Demandbase’s proprietary datasets, we are able to construct a multi-faceted picture of each account’s journey toward pipeline. Advanced machine learning techniques uncover complex patterns of activity across multiple stakeholders at each account, and produce explainable rankings of accounts that allow marketing and sales users to focus their attention on the accounts most likely to convert. We continue to adapt and improve Pipeline Predict through additional data sources and improved modeling techniques, ensuring that it remains a valuable asset for driving pipeline for our customers.
Acknowledgements
Many people have developed and supported the Pipeline Predict project over many years. The Data Science team has continuously refined the model to improve accuracy and explainability across thousands of customers (Carmen Easterwood, Erin Oshinsky, Sukanya Tiwatne, Alex Veen, Sana Ghazi). Our Engineering team makes it possible to train hundreds of models and make predictions for well over half a billion accounts every single day (Manisha Sharma, Josh Cason, Adam Kramer). Our AI/ML product team’s strategic vision for Pipeline Predict has helped us continuously evolve this model to be more useful to our customers, including our recent rollout of Pipeline Predict for Growth (Cullen Wong, Marc Perramond). The UX team’s designs have made it possible for our users to interact with complex models and their predictions with ease (Sarah Neyaz). Finally, we would like to give special thanks to our CEO Gabe Rogol for providing valuable feedback on this post.
Footnotes
[1] Marketing and sales tend to be high-recall environments. That is, marketing and sales professionals cast a wide net because they don’t want to miss out on any potential deals, which leads to low precision (in a Machine Learning sense). This is why Pipeline Predict can bring so much value, because it makes the sales rep much more effective when they focus on the highest-ranked accounts.



